Wat is edge computing en wanneer is het nuttig?
De trend naar digitalisering brengt zowel kansen als risico’s voor de industrie met zich mee omdat digitalisering een grote rekenkracht en hoge opslagcapaciteit vereist. Industriële cloud computing stelt bedrijven in staat de groeiende hoeveelheden gegevens te verwerken en te evalueren om zo de hele waardeketen te optimaliseren.
Wanneer men het heeft over cloud computing, gaat men ervan uit dat er een verbinding is met de cloud via het internet. In veel toepassingen moeten gegevens echter in zeer korte cycli worden verzameld, gecontroleerd en teruggekoppeld naar het proces. In een dergelijk scenario zou een publieke cloud-oplossing niet geschikt zijn vanwege de vertraging in response tijden die op het internet voorkomen. Edge of fog computing-oplossingen worden daarom steeds vaker gebruikt voor dergelijke toepassingen. Maar hoe verschillen deze modellen? Wat zijn de voor- en nadelen?
Edge – directe evaluatie bij de bron
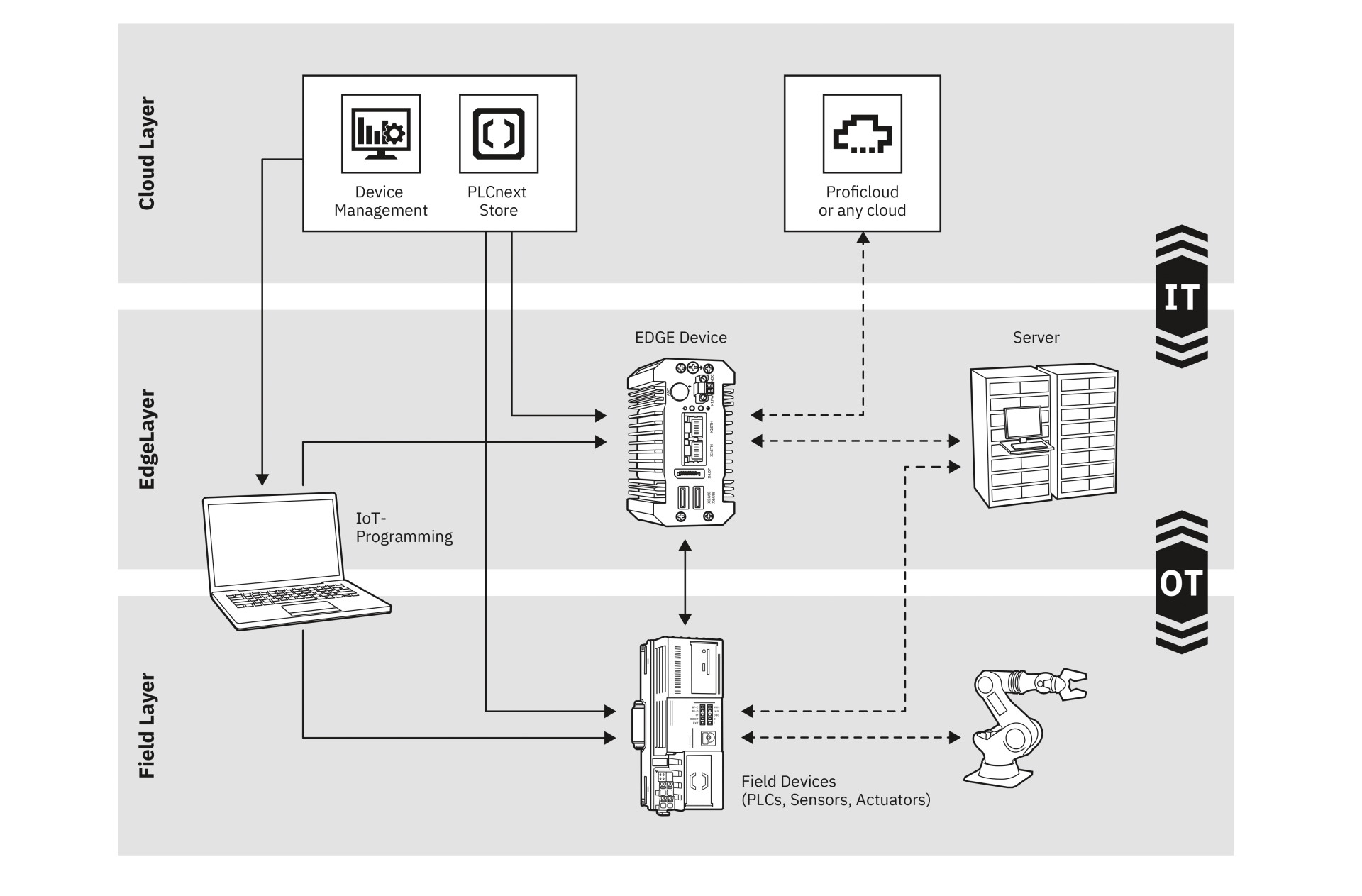
Edge computing biedt de gebruiker de mogelijkheid de geregistreerde gegevens met netwerktechnologieën direct bij de bron te evalueren: “at the edge”. Met edge computing zijn krachtige analysetechnologieën dus vrijwel overal en op elk moment beschikbaar. Op die manier kunnen werknemers, die de toestand van in afgelegen gebieden geïnstalleerde machines en apparaten moeten controleren, veel nauwkeuriger bepalen of onderhoud of reserveonderdelen nodig zijn. Edge computing blijkt dus een alternatief te zijn voor bedrijven die niet direct toegang hebben tot hoge bandbreedte en een snelle route naar de cloud. Dit geldt bijvoorbeeld voor exploitanten van waterwinningsinstallaties, maar ook voor zonne- en windenergiecentrales. Op basis van de hierboven beschreven concepten voor toestandsafhankelijk onderhoud, waarbij machines en apparatuur in realtime worden bewaakt, kunnen de servicekosten aanzienlijk worden verlaagd en kan de productiviteit worden verhoogd.
Centrale verwerking van gegevens van meerdere apparaten
De termen edge computing en fog computing worden vaak synoniem gebruikt en lijken ook sterk op elkaar. Beide benaderingen richten zich op het idee van het verschuiven van rekenkracht van de cloud naar de gegevensbron. Edge en fog verschillen alleen in de mate van deze verschuiving. Bij fog computing worden gegevens van verschillende eindapparaten verzameld en verwerkt op een centrale locatie – zeer vergelijkbaar met het eigenlijke cloud-idee. De plaats waar de gegevens worden verwerkt bevindt zich echter niet in een groot datacenter van de cloud provider. In plaats daarvan wordt een soort “mini-computercentrum” gebruikt, dat zich meestal op dezelfde plaats bevindt als bijvoorbeeld de besturingssystemen die de gegevens aanleveren. Daar worden bijvoorbeeld tijdgevoelige berekeningen gemaakt die van invloed zijn op de machines en die alleen ter plaatse kunnen worden uitgevoerd. Een gedetailleerde analyse en verdere verwerking van de gegevens vindt verderop plaats in het hoger gelegen cloudsysteem.
Edge computing gaat op dit punt nog verder: hier vindt de (voor)verwerking van gegevens daadwerkelijk plaats in de afzonderlijke machines en installaties waarin de gegevens worden gecreëerd. Een dergelijk concept stelt dus hogere eisen aan de lokaal geïnstalleerde apparaten wat betreft rekenkracht, transparantie en toegangsbeveiliging.

Om de voordelen van edge en fog computing te begrijpen, is de eerste vraag die opkomt waarom er niet een puur cloud-systeem wordt gebruikt. Cloud-systemen hebben hun voordelen al bewezen, zoals betrouwbaarheid, kostenbesparing of wereldwijde beschikbaarheid. Zelfs wanneer de cloud bijna onbeperkte opslag- en rekencapaciteit heeft, blijft er een uitdaging: de grote datacentra beschikken over zeer goede netwerkverbindingen, maar dit geldt niet automatisch voor de apparaten die in het veld zijn geïnstalleerd.
Willen bedrijven echt meedoen aan de digitalisering, dan moeten ook de componenten die op afgelegen locaties zijn geïnstalleerd, kunnen worden aangesloten op het Internet of Things (IoT). Een voorbeeld is het besturingssysteem in een zonnepark. Hoewel het waardevolle gegevens verzamelt voor de exploitant, is het alleen via een trage GSM-verbinding verbonden met het netwerk. Hier wordt al snel duidelijk waarom de gegevens niet onmiddellijk naar een cloud-systeem kunnen worden overgebracht: de bandbreedte is gewoon niet voldoende. In dit voorbeeld zorgt edge computing ervoor dat de exploitant van het zonnepark toch zinvol kan werken met de gegevens van het besturingssysteem door een deel van het uit te voeren werk te verplaatsen van de cloud naar de installaties.
Terwijl edge computing gegevens individueel verwerkt in de systemen waar de gegevens worden gegenereerd, verzamelt fog computing gegevens van meerdere systemen op een centrale plek om te worden verwerkt in de cloud. Het belangrijkste verschil is dus de locatie van de twee apparaten.
Dataverbruik ondanks slechte internetverbinding
Over het geheel genomen kan worden gesteld dat edge en fog computing de cloud niet zullen verdringen of vervangen. Ze dienen alleen om de eerdere beperkingen aan het gebruik van de cloud te verminderen. Edge-apparaten zijn in staat om eenvoudige realtime-analyses uit te voeren en sensorgegevens vooraf te verzamelen op basis van specifieke criteria, voordat ze verder worden doorgestuurd naar de cloud. Dit voorkomt onnodige belasting van de cloud-verbinding. Ook de (relatieve) onafhankelijkheid van een internetverbinding en de bijzonder geringe latentie kunnen argumenten zijn voor het gebruik van edge-apparaten in IoT-projecten.